1. 生成式AI简介与发展历程
学习前思考
- 生成式AI与传统AI技术有何本质区别?
- 生成式模型的主要应用领域有哪些?
- 您认为生成式AI的发展会如何改变人类创造性工作的方式?
- 在生成式AI的应用过程中,人类的角色是什么?
在学习本章内容前,请先思考以上问题。带着问题学习,能够帮助您更好地理解和掌握知识点。
生成式人工智能(Generative AI)是指能够创建新内容的AI系统,包括文本、图像、音频、视频等多种形式。与传统的判别式AI(如分类器)不同,生成式AI的目标是创建与训练数据相似但又不完全相同的新内容,具有极强的创造性和适应性。
1.1 发展历程与里程碑
- 早期生成模型(1950s-2000s)
- 马尔可夫链生成文本
- 基于规则的内容生成系统
- 简单的随机过程生成模型
- 深度生成模型兴起(2010-2017)
- 2014年:生成对抗网络(GAN)的提出
- 2015年:变分自编码器(VAE)成熟应用
- 2016-2017年:条件生成模型与风格迁移技术
- 大型语言模型时代(2017-2021)
- 2017年:Transformer架构提出
- 2018年:BERT预训练模型
- 2019年:GPT-2展示强大文本生成能力
- 2020年:GPT-3实现更复杂任务
- 多模态生成革命(2021-至今)
- 2021年:DALL-E、Stable Diffusion等图像生成模型
- 2022年:ChatGPT改变人机交互方式
- 2023年:GPT-4、Claude等多模态大模型
- 2023-2024年:文本到视频生成技术快速发展

图 1-1: 生成式AI主要技术路线与发展历程
1.2 生成式AI的核心能力
- 创造性内容生成:创作文本、设计图像、编写代码、作曲等
- 内容转换与翻译:跨模态转换(文本到图像、音频到文本等)
- 语义理解与上下文感知:理解复杂指令和环境上下文
- 个性化与定制:根据特定风格、需求调整输出
- 交互式协作:与人类进行迭代创作与改进
1.3 生成式AI的主要技术路线
当前生成式AI领域的主要技术路线包括:
| 技术路线 |
代表模型 |
主要优势 |
典型应用 |
| 自回归语言模型 |
GPT系列、LLaMA、Claude |
长文本生成连贯、上下文理解能力强 |
对话系统、写作助手、代码生成 |
| 扩散模型 |
Stable Diffusion、DALL-E、Midjourney |
高质量图像生成、精确控制 |
艺术创作、设计辅助、图像编辑 |
| 生成对抗网络 |
StyleGAN、CycleGAN |
细节真实、风格迁移能力强 |
人脸生成、风格转换、图像增强 |
| 多模态融合模型 |
CLIP、Flamingo、GPT-4V |
跨模态理解与生成 |
图文理解、视觉问答、多模态创作 |
技术趋势
生成式AI正向更大规模、更多模态、更强控制性和更高效率四个方向发展。基础模型(Foundation Models)能力的提升和降本增效是当前研究的重点,而如何实现可靠的控制和提高内容的真实性与准确性是应用落地的关键挑战。
2. 生成模型理论基础
学习前思考
- 概率生成模型和判别模型有何本质区别?
- 为什么生成模型通常比判别模型更难训练?
- 不同类型的生成模型各有什么数学基础?
- 生成模型的评价指标应该关注哪些方面?
在学习本章内容前,请先思考以上问题。带着问题学习,能够帮助您更好地理解和掌握知识点。
要深入理解和开发生成式AI,必须掌握其理论基础。生成模型的核心是学习数据分布,并能从这个分布中采样生成新的数据点。
2.1 概率生成模型基础
生成模型的基础是概率论,主要目标是学习数据的联合概率分布p(x)或条件分布p(x|y):
- 显式密度模型:直接定义并优化数据的概率密度函数
- 隐变量模型:通过引入隐变量z,建模p(x|z)和p(z)
- 隐式密度模型:不直接定义概率分布,但能从中采样
- 能量模型:通过能量函数间接定义概率分布
# 隐变量模型的基本思想示例 (VAE的概率视角)
# p(x) = ∫ p(x|z)p(z)dz
import torch
import torch.nn as nn
# 定义编码器网络(推断网络)q(z|x)
class Encoder(nn.Module):
def __init__(self, input_dim, latent_dim):
super(Encoder, self).__init__()
self.fc = nn.Sequential(
nn.Linear(input_dim, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU()
)
# 输出均值和方差
self.fc_mu = nn.Linear(256, latent_dim)
self.fc_var = nn.Linear(256, latent_dim)
def forward(self, x):
h = self.fc(x)
mu = self.fc_mu(h)
log_var = self.fc_var(h)
return mu, log_var
# 定义解码器网络(生成网络)p(x|z)
class Decoder(nn.Module):
def __init__(self, latent_dim, output_dim):
super(Decoder, self).__init__()
self.fc = nn.Sequential(
nn.Linear(latent_dim, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, output_dim),
nn.Sigmoid() # 假设输出是图像像素值 [0,1]
)
def forward(self, z):
return self.fc(z)
2.2 主要生成模型框架对比
| 模型类型 |
数学基础 |
优势 |
局限性 |
| 变分自编码器(VAE) |
变分推断、最大似然估计 |
训练稳定、可解释的潜空间 |
生成样本细节较模糊 |
| 生成对抗网络(GAN) |
博弈论、极大极小优化 |
高质量、逼真的生成结果 |
训练不稳定、模式崩溃 |
| 自回归模型 |
条件概率分解、最大似然 |
训练简单、适合序列数据 |
生成速度慢、长期依赖困难 |
| 扩散模型 |
非平衡热力学、得分匹配 |
高质量生成、训练稳定 |
采样速度慢、计算成本高 |
| 流模型(Flow) |
可逆变换、变量代换公式 |
精确似然计算、快速采样 |
架构受限、计算复杂度高 |
2.3 生成模型的训练原理
不同生成模型采用不同的训练目标和优化策略:
- 最大似然估计(MLE):最大化观测数据的概率
- 变分下界(ELBO)优化:VAE的训练目标,近似最大似然
- 对抗训练:生成器与判别器的博弈优化
- 去噪训练:扩散模型中预测噪声或清晰信号
- 对比学习:最大化正样本对的相似度,最小化负样本对的相似度
- 自监督学习:从数据本身构造监督信号
2.4 评估生成模型的指标
评估生成模型的质量需要多维度指标:
- 样本质量:真实度、清晰度、细节保真度
- 样本多样性:覆盖数据分布的广度、避免模式崩溃
- 条件控制能力:对生成过程的精确控制程度
- 语义一致性:生成内容的语义合理性
常用定量评估指标:
- IS (Inception Score):评估图像样本质量和多样性
- FID (Fréchet Inception Distance):测量生成分布与真实分布的相似度
- BLEU, ROUGE, METEOR:评估文本生成质量
- PPL (Perplexity):语言模型流畅度评估
- CLIP评分:文本-图像匹配程度
评估陷阱
单一指标往往不能全面反映生成模型的性能。例如,一个只记忆训练集的模型可能有很高的样本质量但缺乏多样性;而过度强调多样性可能导致非真实样本。应综合多种指标和人类评估进行全面评价。
理论与实践的桥梁
尽管生成模型的理论框架各不相同,但它们共享许多设计思想和技术。掌握不同模型间的联系与区别,有助于灵活选择和组合适合特定任务的模型架构。例如,扩散模型可以被看作是带噪声的能量模型,而某些GAN变体可以从VAE的角度进行解释。
3. 大型语言模型架构
学习前思考
- 为什么Transformer架构能在NLP任务中取得突破性进展?
- 大型语言模型的规模与性能之间是什么关系?
- 如何理解大语言模型的涌现能力(Emergent Abilities)?
- 大语言模型的训练过程中有哪些关键技术挑战?
在学习本章内容前,请先思考以上问题。带着问题学习,能够帮助您更好地理解和掌握知识点。
3.1 Transformer架构详解
Transformer是现代大型语言模型的基础架构,其核心特点包括:
- 自注意力机制:实现序列中任意位置的直接信息交互
- 多头注意力:从不同表示子空间捕获信息
- 位置编码:在无序的自注意力中注入位置信息
- 残差连接:缓解深层网络训练困难

图 3-1: Transformer模型架构示意图
3.2 大型语言模型的关键组件
| 组件 |
功能 |
技术特点 |
优化方向 |
| 词嵌入层 |
将词转换为向量表示 |
上下文相关的动态嵌入 |
压缩词表、参数共享 |
| 注意力层 |
计算token间关联 |
多头并行计算 |
稀疏注意力、线性复杂度 |
| 前馈网络 |
非线性特征转换 |
位置级特征处理 |
激活函数优化 |
| 归一化层 |
稳定网络训练 |
层归一化 |
计算效率提升 |
3.3 预训练与微调范式
现代大语言模型采用"预训练+微调"的训练范式:
- 预训练阶段
- 在海量文本上进行自监督学习
- 掌握语言的基础知识和模式
- 通常采用因果语言模型或掩码语言模型目标
- 微调阶段
- 在特定任务数据上进行有监督学习
- 指令微调(Instruction Tuning)
- 对齐微调(Alignment Tuning)
3.4 规模化训练技术
训练大型语言模型面临的主要技术挑战和解决方案:
- 分布式训练
- 数据并行:多GPU复制模型
- 模型并行:模型分片到多设备
- 流水线并行:层级划分计算
- 混合精度训练
- FP16/BF16计算加速
- 动态损失缩放
- 梯度累积
- 内存优化
- 梯度检查点(Gradient Checkpointing)
- ZeRO优化器
- Offload策略
技术趋势
大语言模型正朝着更高效的训练和推理方向发展。稀疏专家混合(MoE)、参数高效微调(PEFT)、量化压缩等技术使得在有限计算资源下也能获得强大的模型能力。同时,模型架构的改进(如Flash Attention、旋转位置编码等)也在不断提升性能。
局限性
尽管大语言模型表现出强大的能力,但仍存在推理不一致、幻觉、知识时效性等问题。理解这些局限性对于安全部署和应用至关重要。同时,模型的可解释性和知识更新机制也是重要的研究方向。
4. 扩散模型与图像生成
学习前思考
- 扩散模型与传统生成模型有何不同?
- 扩散模型的主要应用场景有哪些?
- 您认为扩散模型的发展会如何改变图像生成领域?
- 在扩散模型的应用过程中,人类的角色是什么?
在学习本章内容前,请先思考以上问题。带着问题学习,能够帮助您更好地理解和掌握知识点。
扩散模型(Diffusion Model)是一种基于概率的生成模型,通过逐步去噪过程来生成数据。与传统的生成模型不同,扩散模型在训练过程中需要逐步添加噪声,而在生成过程中则需要逐步去除噪声。
4.1 扩散模型的基本原理
扩散模型的核心思想是通过一个马尔可夫链逐步去噪声,最终生成高质量的数据。这个过程可以表示为:
# 扩散模型的基本思想示例
# 前向过程:逐步添加噪声
# 反向过程:逐步去除噪声
import torch
import torch.nn as nn
# 定义前向过程的噪声函数
class ForwardProcess(nn.Module):
def __init__(self, input_dim, noise_level):
super(ForwardProcess, self).__init__()
self.fc = nn.Sequential(
nn.Linear(input_dim, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU()
)
self.noise_level = noise_level
def forward(self, x):
h = self.fc(x)
return h + self.noise_level * torch.randn_like(h)
# 定义反向过程的噪声函数
class ReverseProcess(nn.Module):
def __init__(self, input_dim, noise_level):
super(ReverseProcess, self).__init__()
self.fc = nn.Sequential(
nn.Linear(input_dim, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, input_dim),
nn.Sigmoid() # 假设输出是图像像素值 [0,1]
)
self.noise_level = noise_level
def forward(self, x):
return self.fc(x) * self.noise_level
4.2 扩散模型的训练与生成
扩散模型的训练和生成过程包括:
- 训练目标:最小化去噪过程的损失
- 生成过程:从噪声中逐步生成数据
4.3 扩散模型的应用场景
扩散模型在图像生成领域有广泛应用,包括:
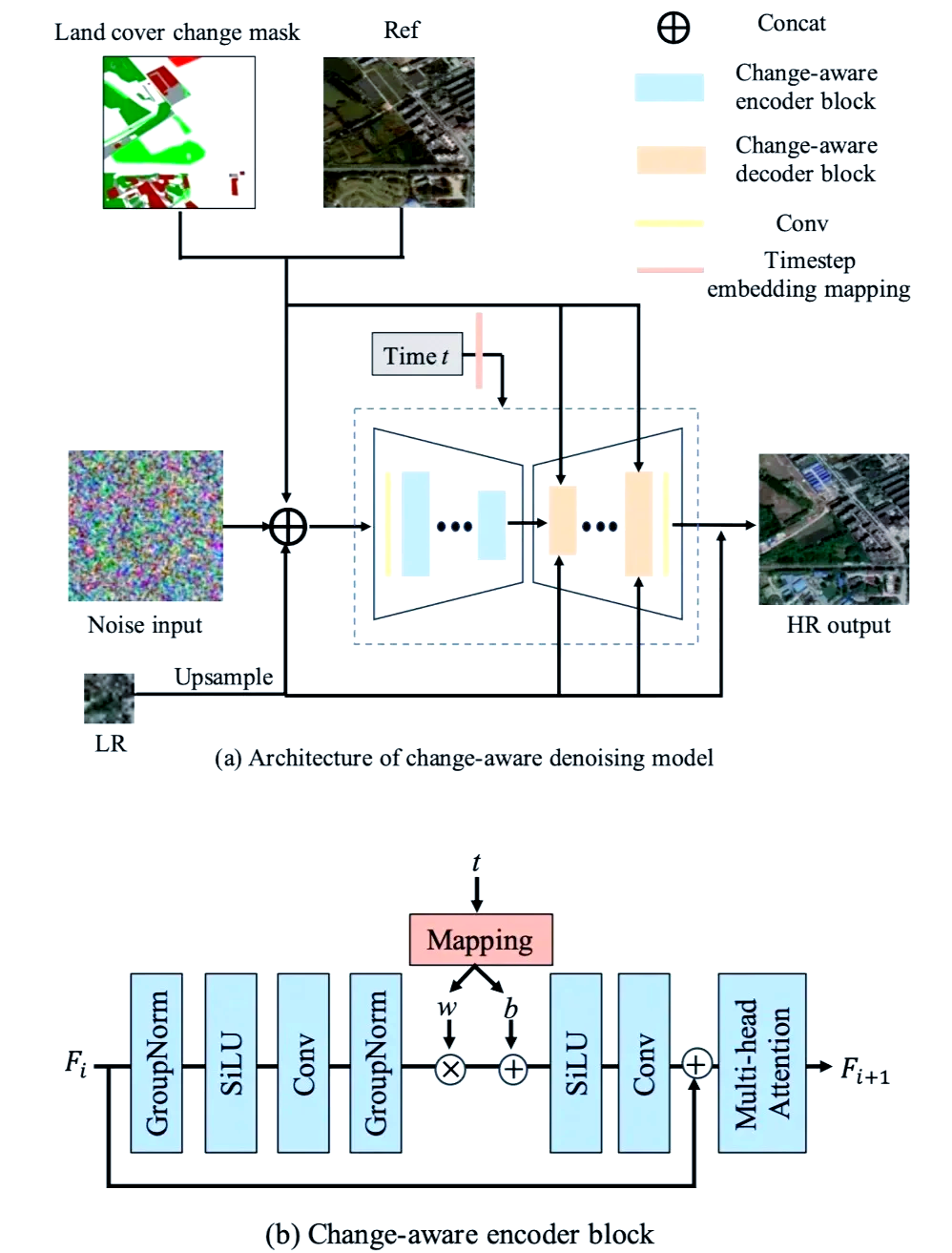
图 4-1: 扩散模型
4.4 扩散模型的局限性与挑战
尽管扩散模型在图像生成领域表现出色,但仍面临一些局限性和挑战:
- 采样速度慢:由于去噪过程的逐步进行,采样速度相对较慢
- 计算成本高:训练和生成过程中需要大量的计算资源
- 模式崩溃:在训练过程中可能出现模式崩溃问题
技术趋势
扩散模型正朝着更高效的训练和采样方向发展。基于分数的生成模型、条件扩散模型等技术正在不断改进采样速度和计算效率。同时,扩散模型的可解释性和多样性生成能力也是重要的研究方向。
5. 多模态生成系统
学习前思考
- 多模态生成系统与单模态生成系统有何不同?
- 多模态生成系统的应用场景有哪些?
- 您认为多模态生成系统的发展会如何改变内容创作领域?
- 在多模态生成系统的应用过程中,人类的角色是什么?
在学习本章内容前,请先思考以上问题。带着问题学习,能够帮助您更好地理解和掌握知识点。
多模态生成系统(Multimodal Generative System)是指能够处理多种类型输入并生成多种类型输出的AI系统。与单模态生成系统不同,多模态生成系统能够同时处理文本、图像、音频等多种输入,并生成相应的输出。
5.1 多模态生成系统的基本原理
多模态生成系统的核心思想是通过一个统一的模型来处理多种类型的输入,并生成相应的输出。这个过程可以表示为:
- 多模态融合:将不同类型的输入融合到一个统一的表示空间中
- 统一生成:从统一的表示空间中生成输出
# 多模态生成系统的基本思想示例
# 多模态融合:将不同类型的输入融合到一个统一的表示空间中
# 统一生成:从统一的表示空间中生成输出
import torch
import torch.nn as nn
# 定义多模态融合模型
class MultimodalModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(MultimodalModel, self).__init__()
self.fc = nn.Sequential(
nn.Linear(input_dim, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU()
)
self.output_dim = output_dim
def forward(self, x):
h = self.fc(x)
return h
# 定义输出层
class OutputLayer(nn.Module):
def __init__(self, hidden_dim, output_dim):
super(OutputLayer, self).__init__()
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
return self.fc(x)
5.2 多模态生成系统的应用场景
多模态生成系统在内容创作领域有广泛应用,包括:
- 文本到图像生成
- 图像到文本生成
- 文本到音频生成
- 图像到音频生成

图 5-1: 多模态生成系统在内容创作中的应用场景
5.3 多模态生成系统的局限性与挑战
尽管多模态生成系统在内容创作领域表现出色,但仍面临一些局限性和挑战:
- 模态间不一致性:不同模态之间的信息不一致性可能导致生成结果质量下降
- 计算成本高:多模态生成系统需要大量的计算资源
- 可解释性差:多模态生成系统的生成过程难以解释
技术趋势
多模态生成系统正朝着更高效的生成和解释方向发展。基于条件生成模型的多模态生成系统、基于对比学习的跨模态生成系统等技术正在不断改进生成质量和解释能力。同时,多模态生成系统的可扩展性和可解释性也是重要的研究方向。
6. 提示工程(Prompt Engineering)
学习前思考
- 提示工程与传统AI技术有何本质区别?
- 提示工程的主要应用领域有哪些?
- 您认为提示工程的发展会如何改变人类创造性工作的方式?
- 在提示工程的应用过程中,人类的角色是什么?
在学习本章内容前,请先思考以上问题。带着问题学习,能够帮助您更好地理解和掌握知识点。
提示工程(Prompt Engineering)是指在AI系统中使用自然语言提示来引导生成过程的技术。与传统的AI技术不同,提示工程能够直接与AI系统进行交互,并根据用户的具体需求生成相应的内容。
6.1 提示工程的基本原理
提示工程的核心思想是通过自然语言提示来引导生成过程。这个过程可以表示为:
- 提示设计:根据具体需求设计自然语言提示
- 生成过程:根据提示生成相应的内容
# 提示工程的基本思想示例
# 提示设计:根据具体需求设计自然语言提示
# 生成过程:根据提示生成相应的内容
import torch
import torch.nn as nn
# 定义提示工程模型
class PromptModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(PromptModel, self).__init__()
self.fc = nn.Sequential(
nn.Linear(input_dim, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU()
)
self.output_dim = output_dim
def forward(self, x):
h = self.fc(x)
return h
# 定义输出层
class OutputLayer(nn.Module):
def __init__(self, hidden_dim, output_dim):
super(OutputLayer, self).__init__()
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
return self.fc(x)
6.2 提示工程的主要应用场景
提示工程在内容创作领域有广泛应用,包括:

图 6-1: 提示工程在内容创作中的应用场景
6.3 提示工程的局限性与挑战
尽管提示工程在内容创作领域表现出色,但仍面临一些局限性和挑战:
- 可解释性差:提示工程的生成过程难以解释
- 计算成本高:提示工程需要大量的计算资源
- 模态间不一致性:不同模态之间的信息不一致性可能导致生成结果质量下降
技术趋势
提示工程正朝着更高效的生成和解释方向发展。基于条件生成模型的提示工程、基于对比学习的跨模态提示工程等技术正在不断改进生成质量和解释能力。同时,提示工程的可扩展性和可解释性也是重要的研究方向。
7. 模型微调与定制化
学习前思考
- 模型微调与传统AI技术有何本质区别?
- 模型微调的主要应用领域有哪些?
- 您认为模型微调的发展会如何改变人类创造性工作的方式?
- 在模型微调的应用过程中,人类的角色是什么?
在学习本章内容前,请先思考以上问题。带着问题学习,能够帮助您更好地理解和掌握知识点。
模型微调(Model Finetuning)是指在预训练模型的基础上,通过少量数据进行有监督学习,以适应特定任务的技术。与传统的AI技术不同,模型微调能够根据具体任务需求对模型进行定制化。
7.1 模型微调的基本原理
模型微调的核心思想是通过少量数据进行有监督学习,以适应特定任务。这个过程可以表示为:
- 微调目标:根据具体任务需求设计微调目标
- 微调过程:在预训练模型的基础上进行有监督学习
# 模型微调的基本思想示例
# 微调目标:根据具体任务需求设计微调目标
# 微调过程:在预训练模型的基础上进行有监督学习
import torch
import torch.nn as nn
# 定义模型微调模型
class FinetuningModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(FinetuningModel, self).__init__()
self.fc = nn.Sequential(
nn.Linear(input_dim, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU()
)
self.output_dim = output_dim
def forward(self, x):
h = self.fc(x)
return h
# 定义输出层
class OutputLayer(nn.Module):
def __init__(self, hidden_dim, output_dim):
super(OutputLayer, self).__init__()
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
return self.fc(x)
7.2 模型微调的主要应用场景
模型微调在内容创作领域有广泛应用,包括:

图 7-1: 模型微调在内容创作中的应用场景
7.3 模型微调的局限性与挑战
尽管模型微调在内容创作领域表现出色,但仍面临一些局限性和挑战:
- 可解释性差:模型微调的生成过程难以解释
- 计算成本高:模型微调需要大量的计算资源
- 模态间不一致性:不同模态之间的信息不一致性可能导致生成结果质量下降
技术趋势
模型微调正朝着更高效的生成和解释方向发展。基于条件生成模型的模型微调、基于对比学习的跨模态模型微调等技术正在不断改进生成质量和解释能力。同时,模型微调的可扩展性和可解释性也是重要的研究方向。
8. 生成内容评估框架
学习前思考
- 生成内容评估框架与传统AI技术有何本质区别?
- 生成内容评估框架的主要应用领域有哪些?
- 您认为生成内容评估框架的发展会如何改变人类创造性工作的方式?
- 在生成内容评估框架的应用过程中,人类的角色是什么?
在学习本章内容前,请先思考以上问题。带着问题学习,能够帮助您更好地理解和掌握知识点。
生成内容评估框架(Generative Content Evaluation Framework)是指用于评估生成内容质量的标准和方法。与传统的AI技术不同,生成内容评估框架能够对生成内容进行全面评估,并给出相应的评分和反馈。
8.1 生成内容评估框架的基本原理
生成内容评估框架的核心思想是通过一系列标准和方法来评估生成内容的质量。这个过程可以表示为:
- 评估标准:根据具体任务需求设计评估标准
- 评估方法:根据评估标准对生成内容进行评估
# 生成内容评估框架的基本思想示例
# 评估标准:根据具体任务需求设计评估标准
# 评估方法:根据评估标准对生成内容进行评估
import torch
import torch.nn as nn
# 定义生成内容评估框架模型
class EvaluationModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(EvaluationModel, self).__init__()
self.fc = nn.Sequential(
nn.Linear(input_dim, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU()
)
self.output_dim = output_dim
def forward(self, x):
h = self.fc(x)
return h
# 定义输出层
class OutputLayer(nn.Module):
def __init__(self, hidden_dim, output_dim):
super(OutputLayer, self).__init__()
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
return self.fc(x)
8.2 生成内容评估框架的主要应用场景
生成内容评估框架在内容创作领域有广泛应用,包括:

图 8-1: 生成内容评估框架在内容创作中的应用场景
8.3 生成内容评估框架的局限性与挑战
尽管生成内容评估框架在内容创作领域表现出色,但仍面临一些局限性和挑战:
- 可解释性差:生成内容评估框架的评估过程难以解释
- 计算成本高:生成内容评估框架需要大量的计算资源
- 模态间不一致性:不同模态之间的信息不一致性可能导致评估结果质量下降
技术趋势
生成内容评估框架正朝着更高效的评估和解释方向发展。基于条件生成模型的生成内容评估框架、基于对比学习的跨模态生成内容评估框架等技术正在不断改进评估质量和解释能力。同时,生成内容评估框架的可扩展性和可解释性也是重要的研究方向。
9. 应用场景与商业化路径
学习前思考
- 应用场景与商业化路径与传统AI技术有何本质区别?
- 应用场景与商业化路径的主要应用领域有哪些?
- 您认为应用场景与商业化路径的发展会如何改变人类创造性工作的方式?
- 在应用场景与商业化路径的应用过程中,人类的角色是什么?
在学习本章内容前,请先思考以上问题。带着问题学习,能够帮助您更好地理解和掌握知识点。
应用场景与商业化路径(Application Scenarios and Commercialization Path)是指AI系统在不同场景中的应用和商业化过程。与传统的AI技术不同,应用场景与商业化路径能够将AI系统应用于实际场景,并实现商业化。
9.1 应用场景与商业化路径的基本原理
应用场景与商业化路径的核心思想是通过一系列场景和方法来实现AI系统的商业化。这个过程可以表示为:
- 场景识别:根据具体需求识别应用场景
- 场景适配:根据应用场景对AI系统进行适配
- 场景实现:根据适配后的AI系统实现应用场景
# 应用场景与商业化路径的基本思想示例
# 场景识别:根据具体需求识别应用场景
# 场景适配:根据应用场景对AI系统进行适配
# 场景实现:根据适配后的AI系统实现应用场景
import torch
import torch.nn as nn
# 定义应用场景与商业化路径模型
class ApplicationModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(ApplicationModel, self).__init__()
self.fc = nn.Sequential(
nn.Linear(input_dim, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU()
)
self.output_dim = output_dim
def forward(self, x):
h = self.fc(x)
return h
# 定义输出层
class OutputLayer(nn.Module):
def __init__(self, hidden_dim, output_dim):
super(OutputLayer, self).__init__()
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
return self.fc(x)
9.2 应用场景与商业化路径的主要应用场景
应用场景与商业化路径在内容创作领域有广泛应用,包括:

图 9-1: 应用场景与商业化路径在内容创作中的应用场景
9.3 应用场景与商业化路径的局限性与挑战
尽管应用场景与商业化路径在内容创作领域表现出色,但仍面临一些局限性和挑战:
- 可解释性差:应用场景与商业化路径的实现过程难以解释
- 计算成本高:应用场景与商业化路径需要大量的计算资源
- 模态间不一致性:不同模态之间的信息不一致性可能导致实现结果质量下降
技术趋势
应用场景与商业化路径正朝着更高效的实现和解释方向发展。基于条件生成模型的应用场景与商业化路径、基于对比学习的跨模态应用场景与商业化路径等技术正在不断改进实现质量和解释能力。同时,应用场景与商业化路径的可扩展性和可解释性也是重要的研究方向。
10. 伦理与安全考量
学习前思考
- 伦理与安全考量与传统AI技术有何本质区别?
- 伦理与安全考量主要应用领域有哪些?
- 您认为伦理与安全考量的发展会如何改变人类创造性工作的方式?
- 在伦理与安全考量的应用过程中,人类的角色是什么?
在学习本章内容前,请先思考以上问题。带着问题学习,能够帮助您更好地理解和掌握知识点。
伦理与安全考量(Ethics and Security Consideration)是指在AI系统开发和应用过程中,考虑伦理和安全问题的技术和方法。与传统的AI技术不同,伦理与安全考量能够确保AI系统的安全性和可靠性。
10.1 伦理与安全考量的基本原理
伦理与安全考量的核心思想是通过一系列原则和方法来确保AI系统的安全性和可靠性。这个过程可以表示为:
- 伦理原则:根据伦理原则设计AI系统
- 安全方法:根据安全方法确保AI系统的安全性和可靠性
# 伦理与安全考量的基本思想示例
# 伦理原则:根据伦理原则设计AI系统
# 安全方法:根据安全方法确保AI系统的安全性和可靠性
import torch
import torch.nn as nn
# 定义伦理与安全考量模型
class EthicsModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(EthicsModel, self).__init__()
self.fc = nn.Sequential(
nn.Linear(input_dim, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU()
)
self.output_dim = output_dim
def forward(self, x):
h = self.fc(x)
return h
# 定义输出层
class OutputLayer(nn.Module):
def __init__(self, hidden_dim, output_dim):
super(OutputLayer, self).__init__()
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
return self.fc(x)
10.2 伦理与安全考量的主要应用场景
伦理与安全考量在内容创作领域有广泛应用,包括:

图 10-1: 伦理与安全考量在内容创作中的应用场景
10.3 伦理与安全考量的局限性与挑战
尽管伦理与安全考量在内容创作领域表现出色,但仍面临一些局限性和挑战:
- 可解释性差:伦理与安全考量的实现过程难以解释
- 计算成本高:伦理与安全考量需要大量的计算资源
- 模态间不一致性:不同模态之间的信息不一致性可能导致实现结果质量下降
技术趋势
伦理与安全考量正朝着更高效的实现和解释方向发展。基于条件生成模型的伦理与安全考量、基于对比学习的跨模态伦理与安全考量等技术正在不断改进实现质量和解释能力。同时,伦理与安全考量的可扩展性和可解释性也是重要的研究方向。
本教程的其他章节正在开发中,包括:
- 大型语言模型架构
- 扩散模型与图像生成
- 多模态生成系统
- 提示工程(Prompt Engineering)
- 模型微调与定制化
- 生成内容评估框架
- 应用场景与商业化路径
- 伦理与安全考量
返回首页